
01
Volume
252K+ enterprise software products mapped across 2,606 live categories with 2.4M+ aggregated reviews · the broadest structured enterprise-software graph in production.
The Data Foundation
Last refresh · 55 days agoThe PYRAMYD Product Graph is the most comprehensive, structured, and continuously refreshed knowledge base of enterprise software ever assembled.
The enrichment pipeline
Each taxonomy node is enriched through the same 10 field groups in canonical tab order. Watch a single category fill in · every cell carries its model, prompt hash, and citation set.
Enrichment progress
100%
Filling Pulse …
Every taxonomy node (category, industry, country, job, product) carries the same 10 field groups in this canonical order. Same shape across taxonomies = one mental model for analysts, one API for connectors, one audit row per cell.
Enrichment on demand
The same runner powers every scope. You pick what to refresh; PYRAMYD pays for most of it because every enrichment compounds back into the shared graph.
Taxonomy
1 of 5All rows · all 10 groups · all cells. Held under an advisory lock so the run is atomic.
Row
2 of 5One node (e.g. one category, one country) refreshed across every enrichable field group.
Column
3 of 5One field across many rows · ship a new dimension to your whole taxonomy at once.
Group
4 of 5One field group (e.g. demand, landscape, compliance) refreshed across the rows you pick.
Cell
5 of 5One field on one row · the cheapest unit. Costs cents and runs in seconds.
Why we subsidize
When you enrich a row, PYRAMYD keeps a copy in the shared product graph. That means your $X of LLM + retrieval spend funds the next thousand customers asking the same question · so we charge you the marginal compute, not the sticker price.
What you pay
Cell · 1 field, 1 row
~3-8 LLM calls + 1 embedding
$0.02 · $0.08
Row · 1 node, 10 groups
~120-180 LLM calls + verification
$0.70 · $1.40
Taxonomy · 4,329 jobs
Atomic run, advisory-locked
$3K · $6K
Ranges reflect frontier-model selection (Claude Opus, GPT-5) vs. budget-tier (Haiku, Mini) · same verification gate either way.
Cell-level provenance, live in the workspace
A real Chrome capture from the production graph · the provenance popover shows freshness, quality score, confidence, sources, raw payload, and full revision history for the field the user clicked.
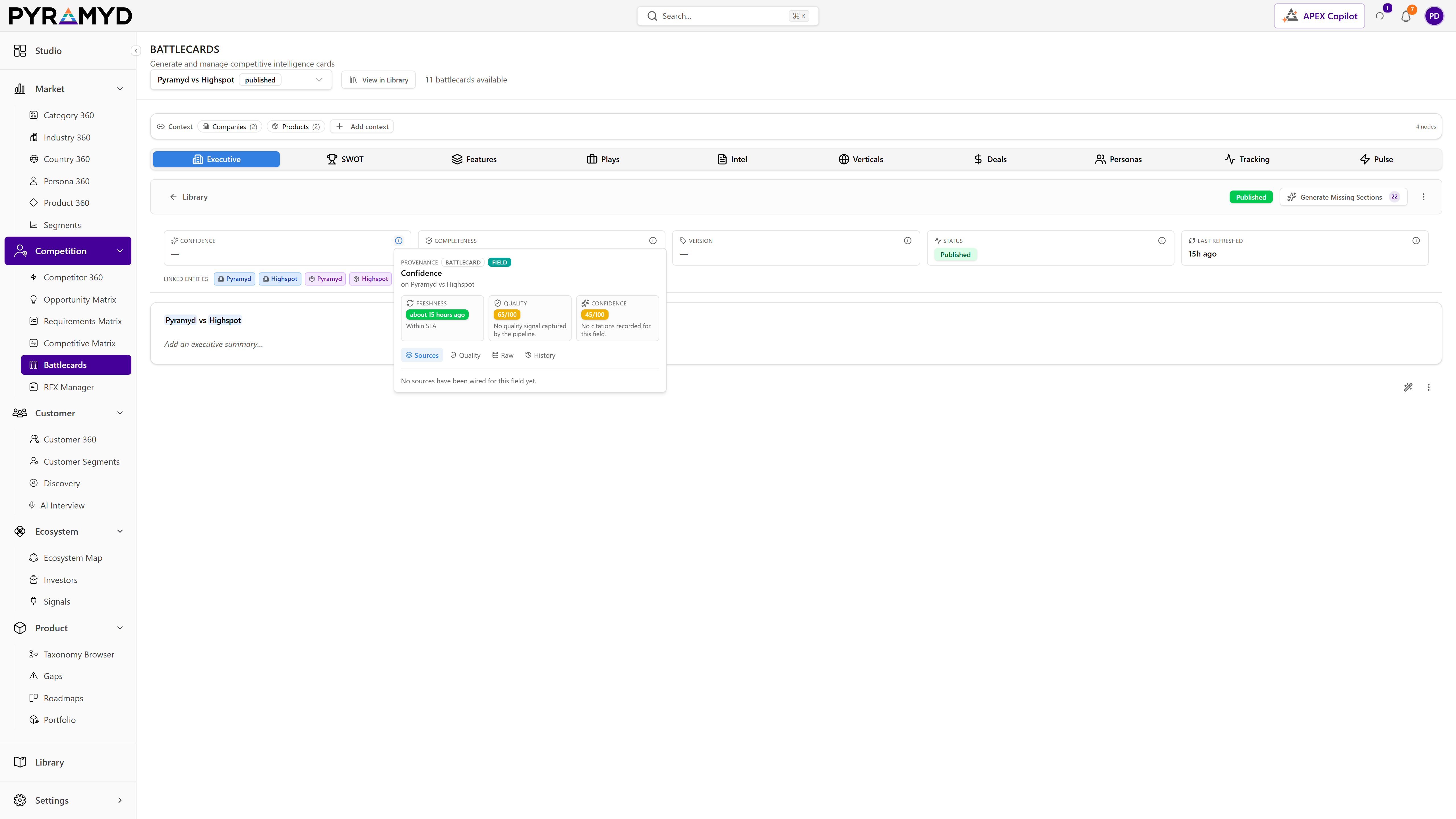
Live capture from the production graph · Battlecards module · Provenance popover open on a Strengths field.
Freshness
How recently the field was verified against its source. Within SLA in this example · refreshed 1 day ago.
Quality & Confidence
Quality is the underlying signal strength (65/100 here). Confidence is how sure the model is the extraction is correct. Both rendered as discrete scores, not heuristic stars.
Sources · Raw · History
Three tabs · Sources lists every URL fingerprinted into the field, Raw shows the model's captured payload byte-for-byte, History is the audit log of every previous value.
What's in the graph
A real Salesforce-shaped record from the production graph. Every field is typed, every FK traversable, every signal carries provenance.
Vendor node · production shape
{
"id": "8a7c5f1e-...",
"name": "Salesforce",
"description": "Customer relationship...",
"country": "United States",
"industry": "Software · SaaS",
"size": "Large Enterprise",
"reviewCount": 18420,
"productCount": 47,
"categoryCount": 23,
"dataQuality": {
"verifiedAt": "2026-05-28T14:11:02Z",
"confidence": 0.94,
"sourcesCount": 12
},
"provenance": {
"sourceUrl": "https://salesforce.com/about/",
"retrievedAt": "2026-05-28T08:22:17Z",
"refreshCadence": "weekly"
}
}Every field is queryable. Every foreign key resolves. Every signal links back to a source URL with a retrieval timestamp.
MCP server response · getVendor(slug="salesforce")
{
"vendor": { "name": "Salesforce", "id": "..." },
"products": [
{ "name": "Sales Cloud", "score": 4.4,
"reviews": 9821, "category": "CRM" },
{ "name": "Service Cloud", "score": 4.3,
"reviews": 4102, "category": "Help Desk" }
],
"topCategories": ["CRM", "Marketing Auto",
"Sales Engagement", "Field Service"],
"competitors": [
{ "name": "HubSpot", "score": 4.5 },
{ "name": "Microsoft Dynamics", "score": 4.2 }
],
"citations": [
{ "field": "reviewCount",
"source": "g2.com/.../salesforce",
"retrievedAt": "2026-05-28T..." }
]
}Any agent · Claude, ChatGPT, GitHub Copilot, your internal LLM · can query the graph through the MCP server. Responses come back typed, cited, and traversable.
The Six Layers
Each layer reinforces the others. Together they form a foundation that gets deeper every week · not narrower.
Internal estimate: 12–24 months and $1–3M of focused engineering + data acquisition spend to replicate from scratch.
Depth × Breadth
Every taxonomy carries the same 10 field-group schema · overview, pulse, demand, market, landscape, trends, economics, operations, compliance, capabilities. Multiply row count × column width × 10 dimensions and the foundation is structured, not just big.
| Node | Rows | Cols | Structured points | Refresh |
|---|---|---|---|---|
| Products | 251,835 | 288 | 72.5M | Weekly · per-source cadence |
| Reviews | 2,447,964 | 95 | 232.6M | Weekly · 200+ review sites |
| VPT features | 2,870,530 | 190 | 545.4M | Weekly · vendor changelogs |
| Companies | 251,835 | 273 | 68.8M | Monthly · funding + hiring |
| Categories | 2,606 | 154 | 401,324 | Weekly · LLM-enriched |
| Industries | 742 | 106 | 78,652 | Monthly · LLM-enriched |
| Countries | 1,738 | 90 | 156,420 | Quarterly · regulator-tracked |
| Jobs | 4,329 | 76 | 329,004 | Quarterly · LLM-enriched |
| Total | ~5.8M | across 8 node types | ~620M structured data points | Rolling enrichment |
Enrichment coverage
Every row in each taxonomy carries an LLM-grounded enrichment payload · google-search grounding, citations preserved, model + timestamp tracked per row. Pulled live from production.
Categories
100%
2,606 of 2,606 rows enriched
4 models · google-search grounded
last enriched: 2026-05-29
Industries
100%
163 of 163 rows enriched
3 models · google-search grounded
last enriched: 2026-02-14
Countries
100%
249 of 249 rows enriched
3 models · google-search grounded
last enriched: 2026-01-18
Jobs
100%
4,329 of 4,329 rows enriched
2 models · google-search grounded
last enriched: 2026-05-15
Refresh cadence
The default cadence is weekly · categories, industries, countries, jobs, products, reviews all re-enriched on a 7-day rolling cycle. When a customer needs an update sooner, any node can be re-enriched in real time from the workspace; token consumption applies.
Refreshing · categories
The compounding foundation
The default cadence is weekly · every taxonomy, every product, every connector-sourced signal re-enriches on a 7-day rolling cycle. Battle cards, dashboards, and APEX answers all carry the latest evidence without an analyst lifting a finger.
Weekly
Default platform-wide refresh
Realtime
User-triggered per node · token usage applies
24/7
Connector ingestion · 1K+ signal sources
Weekly
Default cadence · every node, every taxonomy
Every category, industry, country, job, product, and connector-sourced signal re-enriches on a 7-day rolling cycle. Battle cards, dashboards, and APEX answers all carry the latest evidence without an analyst lifting a finger.
Real-time
User-triggered · any node, on demand
Need fresher data right now? Hit refresh on any node from the workspace and the enrichment job runs immediately. Token consumption applies per re-enriched row, billed against your workspace budget.
Continuous
Always-on signal ingestion
Review feeds, competitor website diffs, funding announcements, hiring signals, and press wires stream into the graph as they happen. Surfaced into Competitor 360 and Alerts within hours of the source event.
Why this matters
Every node carries a verified-at timestamp. When a review changes, a category shifts, or a competitor ships a price change, the battle card refreshes automatically on the weekly cycle · and any analyst can force an instant refresh on the rows that matter most this morning, with provenance preserved on every cited claim.
Live Today
These aren't roadmap numbers. Every figure here is queryable on the platform today.
252K+
Enterprise software products tracked across 2.6K categories
2.4M+
Aggregated software reviews from 200+ review sources
1K+
Live signal sources, refreshed on per-source cadence
88
Universal node types across the entire graph schema
200+
Pre-transformed connectors, 183 bi-directional
3.08×
Live query speedup vs. baseline (2,519ms → 818ms)
88 Universal Node Types
The graph schema is the foundation. Ten categories span people, entities, products, revenue, finance, operations, comms, content, data, and systems · and every edge between them is a query the graph can answer.
People
Contacts · roles · positions · interviews
Entities
Companies · teams · workspaces · segments · locations · countries · industries
Products
Products · categories · features · releases · reviews
Revenue
Deals · orders · pipelines · contracts · campaigns · cadences · battle cards
Finance
Transactions · postings · ledgers · periods · budgets · forecasts · filings
Operations
Ideas · requirements · issues · projects · roadmaps · cycles · objectives · capabilities · processes
Comms
Communications · chats · channels · events
Content
Documents · articles · snippets · sheets · slides · notebooks · canvases · forms · files · folders · transcripts
Data
Datasets · catalogs · connectors · transformations · prompts · agents · runs · models · experiments · metrics · signals · dashboards
Systems
Repositories · branches · commits · credentials · settings · activities · devices · alerts · applications · policies · services
Every Signal Cited
Every node and every signal carries the metadata regulators want and the metadata sales leaders need: source, time, model, confidence, verification status.
Every signal links back to the real source · a press release, a review, a vendor changelog, a regulatory filing.
When the signal was captured. When it was last re-verified. When the source itself was updated.
Which model wrote the enrichment. Prompt version. Token count. Cost. Confidence score per field.
Verified · Needs Review · Disputed. A 2-gate audit (completeness + content) before any row reaches APEX.
When a customer asks "where did this come from?" they have a defensible, regulator-ready answer.
In 30 minutes we'll pull live data for your top 5 competitors, walk the graph, and show APEX answer a multi-hop question with every citation traceable to source.